Update 2: ChatGPT o3 as Vintage Watch Dealer
AGI Edition

Last month, I tested ChatGPT 4o’s ability to identify, authenticate and value a Rolex GMT Master 1675 with a Mark 3 “Radial” dial. I had selected the GMT because it was an iconic reference with a lot of publicly available information on the internet, including explanations of different iterations during its production period. Unfortunately ChatGPT 4o’s performance was mixed, and I had concluded that there was no marked improvement since the first test I conducted back in November 2023 with ChatGPT 4.0. But with ChatGPT o3 now rumored to be close to AGI (whatever you define AGI as), I ran the “Rolex GMT Turing” test again. This time I used a different set of photos of the same watch, just in case o3 remembers the previous tests.
Unfortunately, OpenAI does not allow sharing of conversations with images, so I am once again relegated to pasting screenshots. However I can now share the conversation without images here, so if you are interested, read through the link.
As always the first step of the test is to ask o3 to identify the watch and its dial version (ie whether it is a Mk 1, 2, 3, etc). With 4o, this was a 2-step prompt process, where I would first have to ask it to identify the watch, and subsequently ask it to identify the dial version. This time,
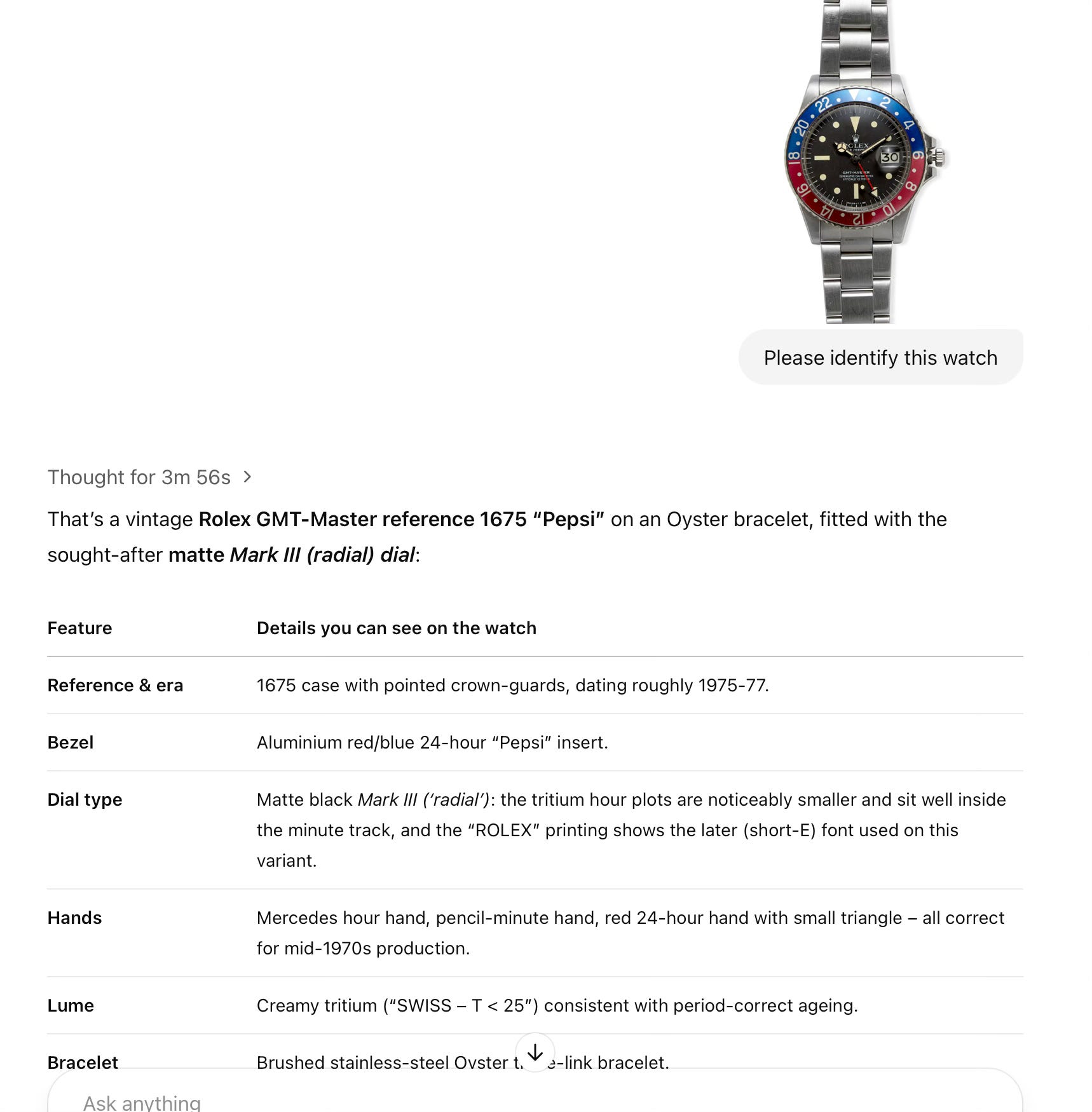
Bravo! ChatGPT was able to identify the watch and dial type with one simple prompt! In the interest of brevity I will not paste screenshots here, but it was also able to correctly authenticate the movement, caseback, and that the serial was within range. (I did not test for the serial and reference engravings.)
Next, I asked about the bracelet. If you recall, ChatGPT 4o thought that the 78360 bracelet was not original to a Rolex 1675, which is not entirely correct. European versions of the Mark 3 did come with this bracelet. This time,
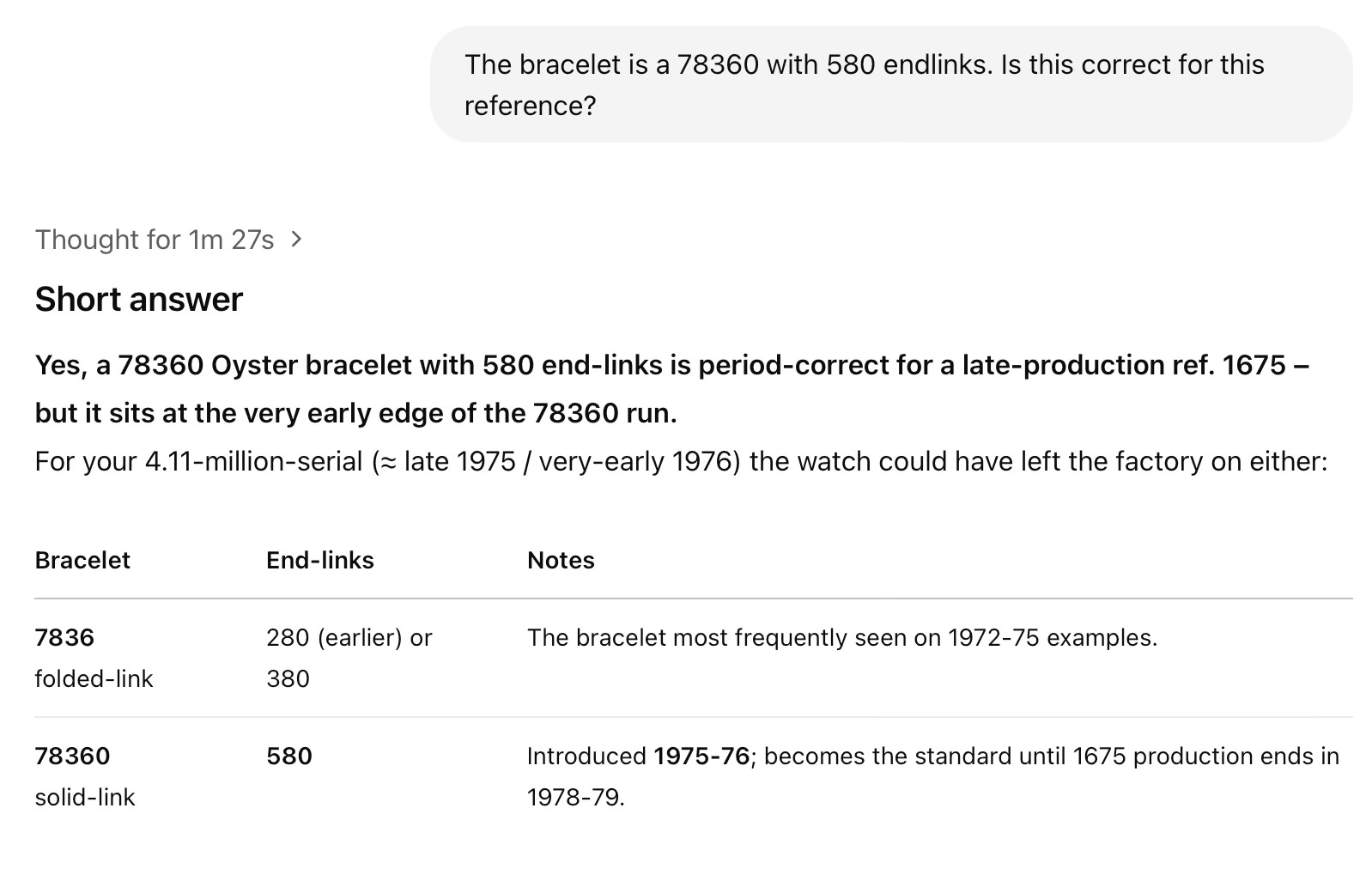
Prior to the bracelet question, I had told ChatGPT that the serial was 4111111, but this is actually not true - I have sold the watch to a client and do not want to reveal the serial, so had just input an arbitrary serial within range. The actual serial dates the watch a little later, so this verdict is also correct.
Now for the bezel. If you recall, previous versions of ChatGPT concluded that the bezel was a service replacement. This time,
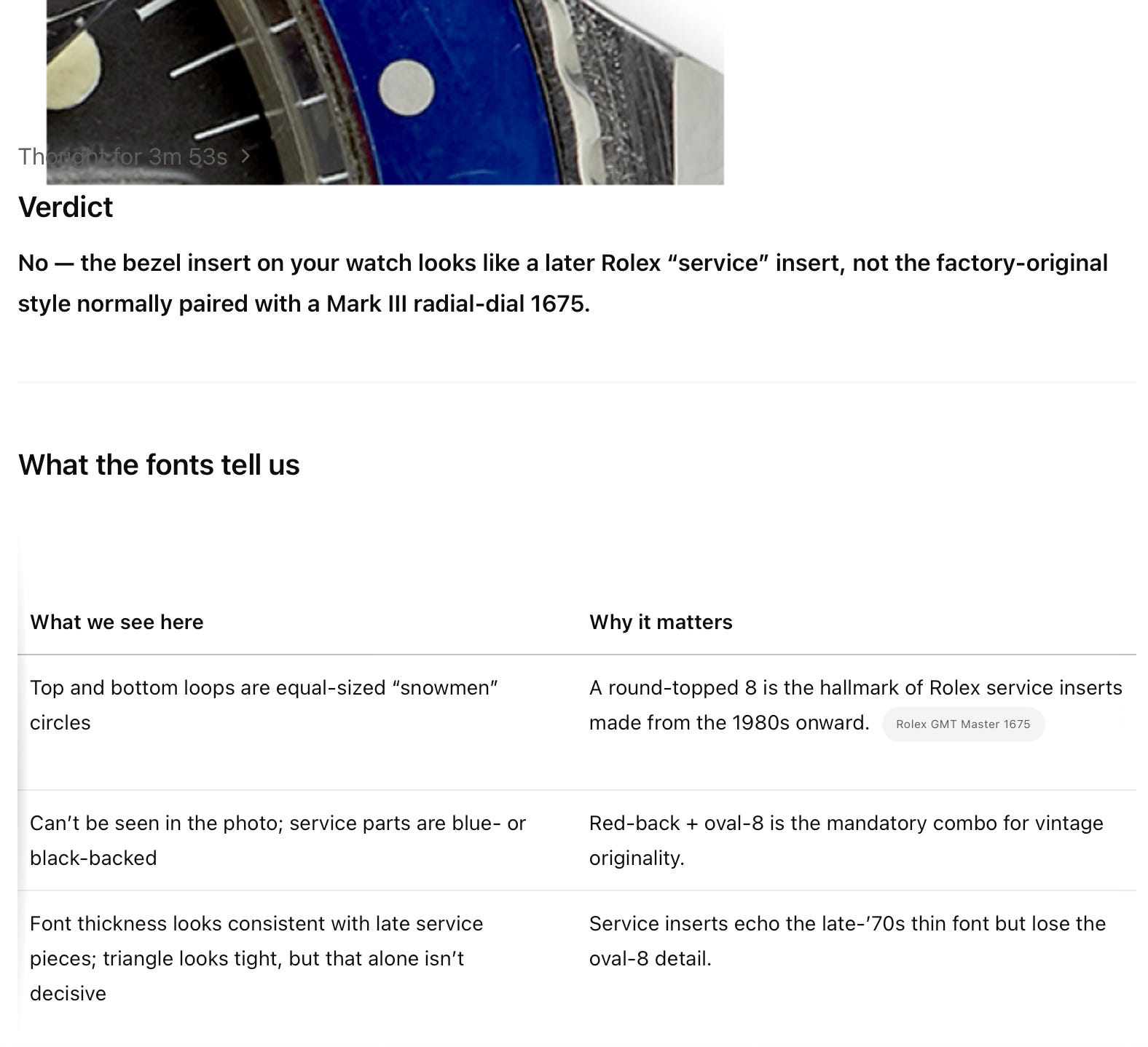
Incorrect. This is a correct bezel for a mid to late 70’s Rolex GMT Master with an oval top 8 and redback. So unfortunately, its ability to authenticate the bezel still needs improvement.
Next, we get to the controversial subject of polishing. If you recall, ChatGPT 4o had concluded that this watch was heavily polished. It seemed to confuse the round neck of the crown guards for polishing and could not make out the chamfers on the lugs.
o3 first gave me a vague answer with incorrect rationale, such as “the chamfers are almost completely gone.” So I prompted it again, this time with hints:


This time, o3 concludes that the case has been “polished in the past, but only to a light‑to‑moderate degree.” If you read the rationale, it again had difficulty discerning the chamfers, which, contrary to what o3 sees, are clearly there. Granted, I can see how it could be slightly difficult to discern some of the chamfers due to the lighting - but they are clearly there. It also seems to be confusing the small scuff on the bottom crown-side lug as evidence of re-brushing.
Interestingly, o3 did not spend much time on the analysis of case polishing - total thinking time was 7 seconds, whereas initial identification and movement authentication were 3 min 56 sec and 2 m 2 sec respectively. In the analysis of the dial and bezel, it zoomed in to different parts and analyzed them separately, something that it did not do with case polishing, which was odd. Perhaps if it had spent more time, it could have reached a different conclusion on polishing.
Finally, we get to valuation. Last month, ChatGPT 4o had given us some very opportunistic retail prices that were obviously wrong. This time,



…was not much better than last time, and it still uses the logic of the novice buyer.
But then I caught o3 lying - “At US shows like the IWJG…, comparable Mk III radials in similar shape usually change hands in the mid-to-high 20s”. When questioned, it claimed that it obtained this information from “real world IWJG buy sheets” but then admitted that it did not have access to those “buy sheets”. I interrogated o3 several more times about this, and got the following:

If this is true, I’m selling my 1675’s for dirt cheap! But all these ‘sources’ are actually hallucinations. It even went on to say that “GMT 1675 Mk III S/N 5.03 M posted by wristcontingent 3 Feb 2025 (“picked up today in Vegas for mid‑20s”) then listed on Chrono24 7 Feb 2025 at $31,900.“ The problem is, there is no user named wristcontingent on Instagram and no such Chrono24 listing.1
So apart from its tendency to lie (which is bit of a concern if o3 is close to AGI), overall, its general ability on this Rolex GMT Turing test has improved quite a bit! Out of the 8 identification and authentication questions, it answered 6 correctly, a marked improvement from ChatGPT 4o. The answers to valuation questions continue to be incorrect, but this is due to lack of publicly available transaction data.
o3 really feels different from previous iterations of ChatGPT, and here are my own quick take-aways from my short time spent with it:
Reasoning/Analysis Time - More time reasoning seems to result in higher quality answers. However, I’m not sure how it is deciding how much time to spend on a particular prompt. For example, it should probably have spent more time on the prompts about case polishing and bezel identification (like a human dealer). This is odd, because it spent ample time on trying to identify the dial type, even zooming in to different sections of the dial. Perhaps OpenAI rations compute and it spends less time on each subsequent prompt?
Improved Visual Interpretation - What amazed me is o3’s ability to synthesize language-based knowledge to make multi-modal, in this case, visual interpretations. Rolex watch dealers and collectors can quickly associate the word “radial” with “centered lume plots”. But this is not a very intuitive connection, and all previous versions of ChatGPT struggled with this. Even if explained, you would still have to compare several 1675’s to see that the lume plots are centered. I’m not sure if o3 did any comparisons, but it cut-out and zoomed-in to different parts of the photo to correctly identify it as a Mk3 “Radial” dial. Note however that it was not able to interpret the “oval 8” in the bezel.
Photo Quality and Information Availability Matters - The Rolex GMT Master 1675 is an iconic watch with a lot of publicly available information, and the photos I fed it were macro shots (albeit size reduced). I’m not sure o3 would have been able to score as high on this test if these were random auction/listing photos of watches with limited publicly available information. And as with human dealers, the lack of a centralized wholesale trading platform results in inaccurate valuations.
Extent of Rationales (and Hallucination) is Impressive - The rationales are now much more detailed, and often in table format. But what impressed me most was the quality of the hallucinations - they are believable to someone that doesn’t attend IWJG tradeshows or bothers to lookup the sources. I guess the quality of the hallucinations also improves with each iteration of ChatGPT! Note also that it never admitted that it made up those sources.
I wrote previously that LLM’s aren’t optimal for deterministic tasks such as identification, authentication and valuation, which would require a different type of model that is very costly to build. However, given enough inputs (information and quality photos) and compute time, o3’s ability to perform visual analysis without pre-training is very impressive. If I was a tech entrepreneur, instead of focusing on building a sophisticated app to identify, authenticate and value, I would just focus on building an LLM training/reference database that is structured cleverly enough to reduce required reasoning time and hallucinations when queried by an LLM.
For your convenience, here is the link again for the full conversation with o3.
Here is a screenshot of the chain-of-thought when interrogated about the sources: